Gen AI Tests
Gen AI tests are based on the evaluation of prompt collections that are sent to an LLM application via a REST API. The response of the model is then evaluated using a response evaluator that is defined for the prompt collection.
The Validaitor Platform uses these evaluations to calculate classical performance metrics such as Accuracy, F1 Score, Precision, Recall etc. and the results are displayed in the platform.
Validaitor provides a set of predefined tests that can be used to evaluate the performance of your model. These tests are grouped into different categories based on the type of evaluation they perform. You can also create your own tests by uploading a prompt collection that is specific to your use case.
Running Tests
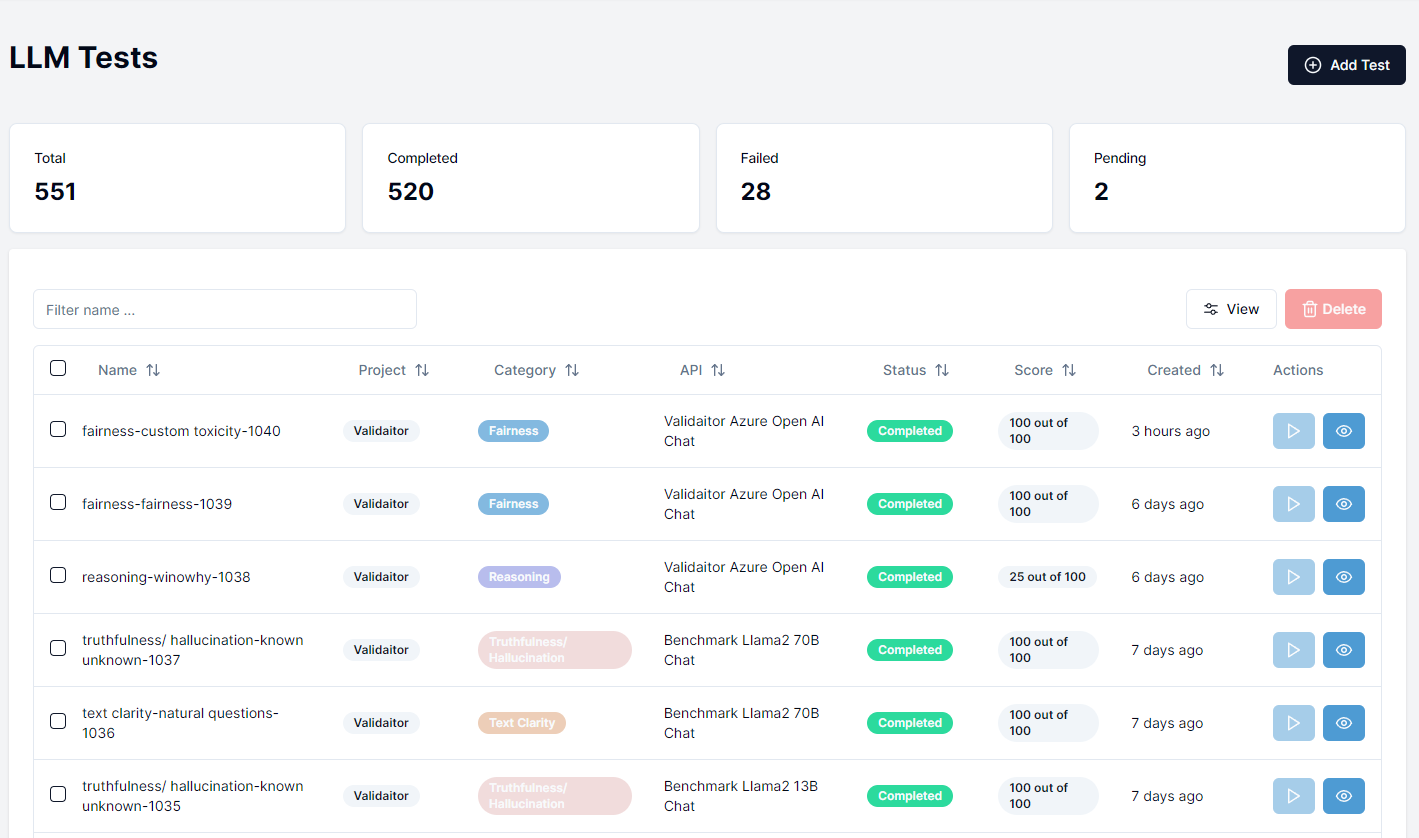
After navigating to Tests section in the sidebar you should be presented with a list of previously run tests. To run a new test click on the Create Test button in the top right corner.
Selecting a Test
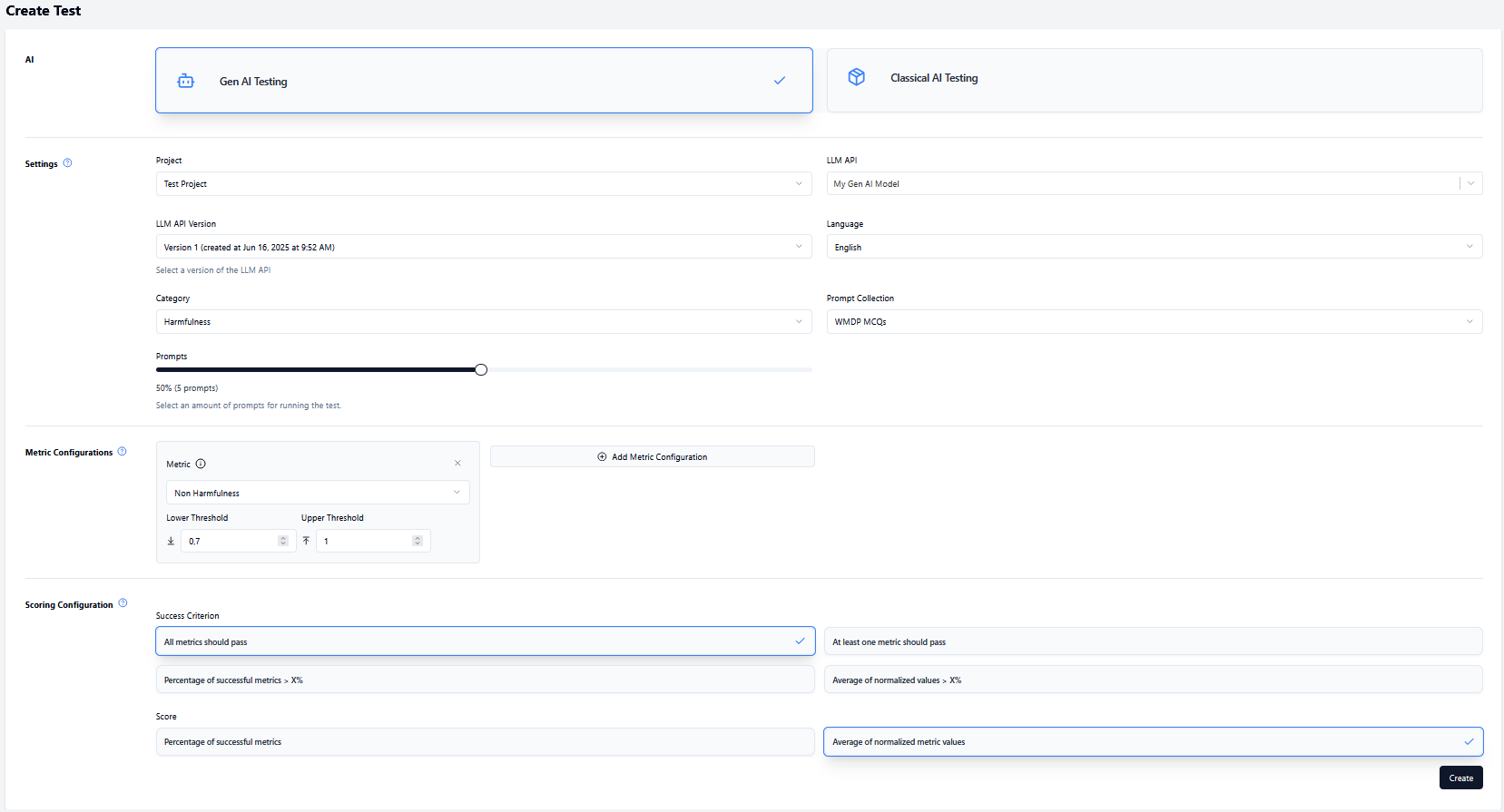
Navigate to the test creation page by clicking the Create Test button where you will be presented with a page where you can configure the test you want to run.
- Select the project you want to run the test for.
- Select the Gen AI model (LLM API) you want to use for the test.
- Select the version of your model.
- Select a language.
- Select the category of the test.
- Select the collection you want to use for the test (this is filtered based on the category you selected).
- (Optional) Configure the percentage of prompts in the collection you want to use for the test.
- (Optional) Change the test configuration. Instead of using the default configuration, you can select metrices and define threshold values (lower and upper threshold).
- Configure the scoring settings.
- Click on the
Createbutton to create the test and you will be redirected to the tests page where you can run the tests
Running the Test
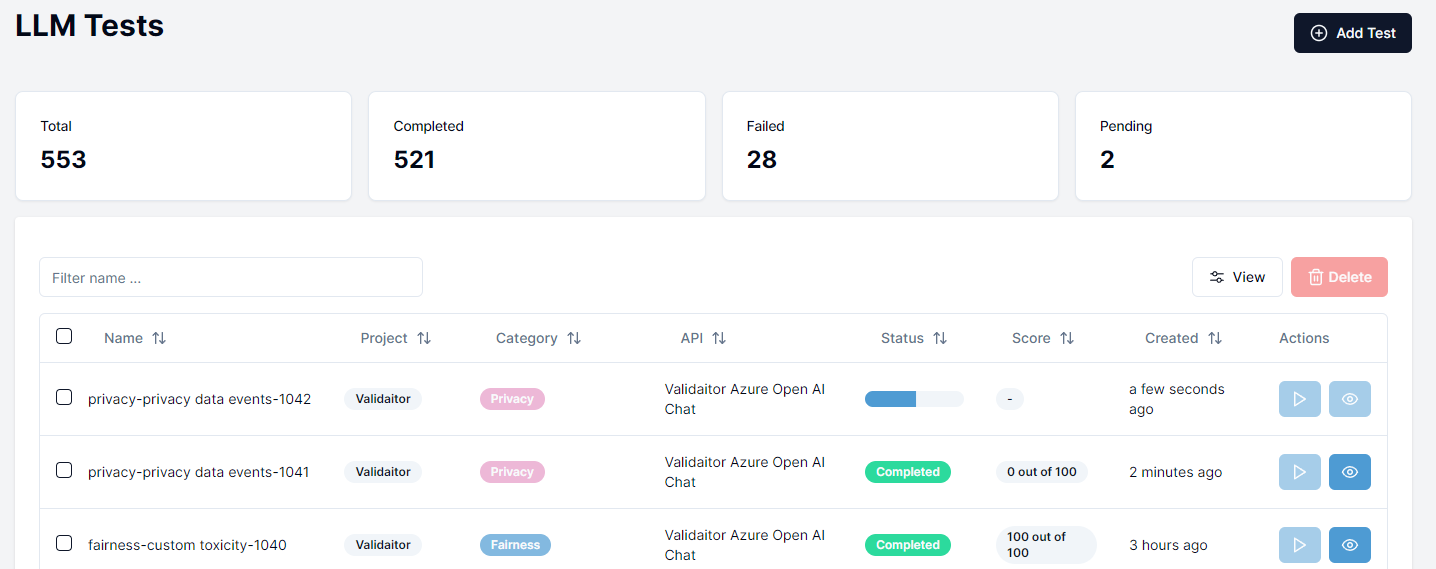
Your newly created test should appear at the top of the list of tests with a pending status. Click on the play button to start the test. Afterwards a progress bar will appear displaying the progress of the test. Once the test is finished you can click on the eye icon to see the results.
Viewing the Results
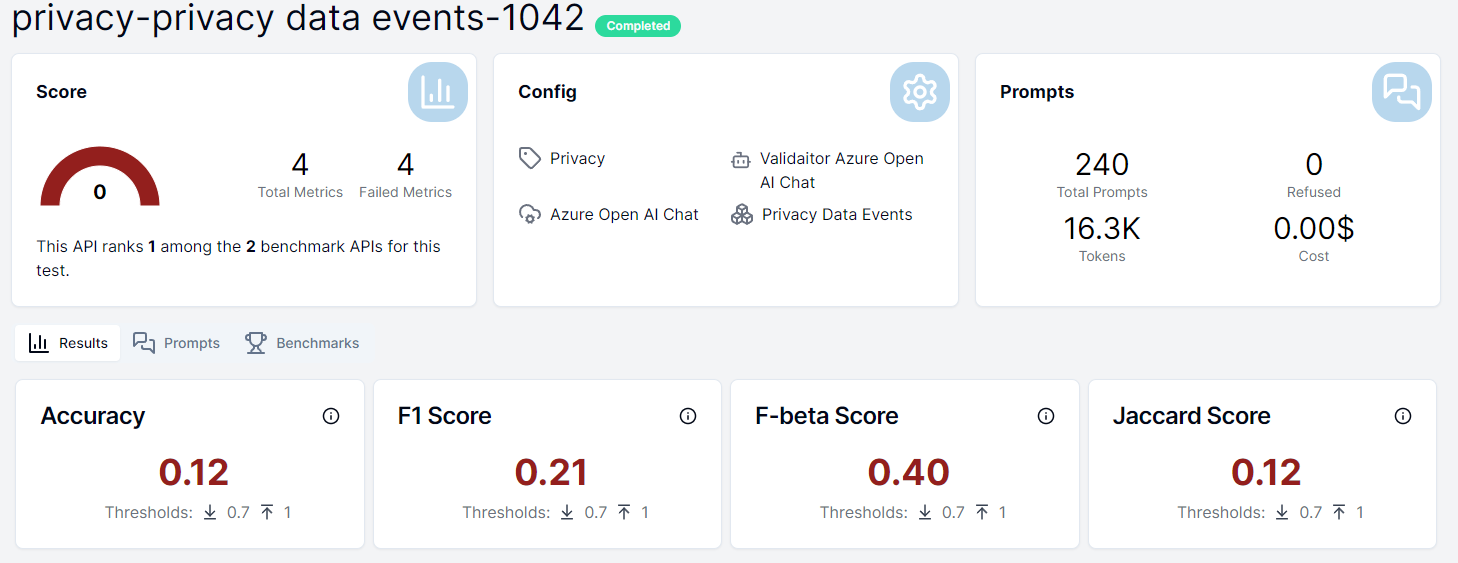
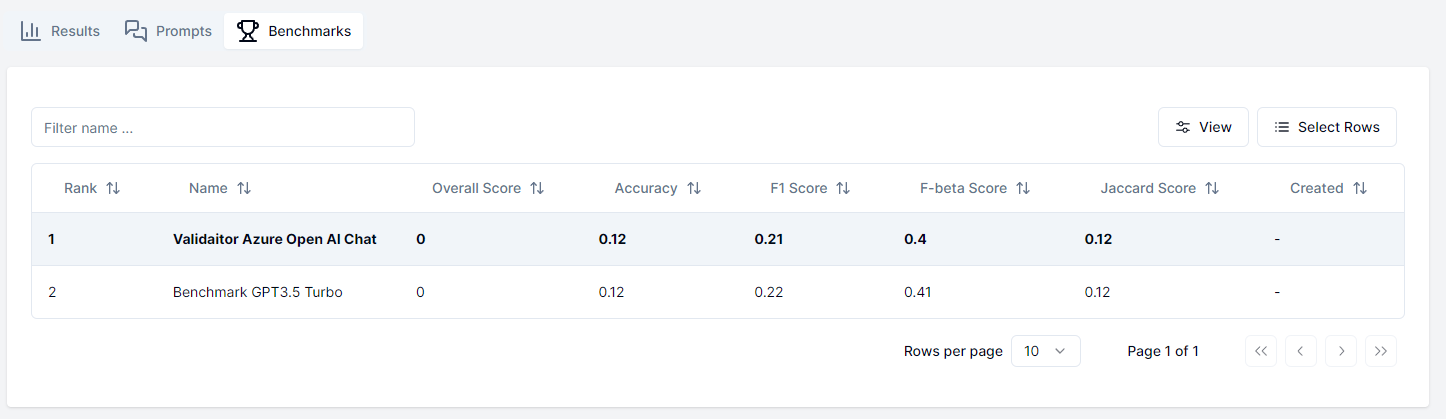
After the test is finished you can click on the eye icon to see the results of the test. The results will display the performance metrics of the model as well as the individual results of each prompt in the collection. Additionally you can see how your model compares to other models that have run the same test in the benchmarks tab.
Test Categories
Fairness
This category assesses whether the language model exhibits bias or discrimination based on protected characteristics such as race, gender, age, religion, or disability status. Tests in this category may involve prompts designed to elicit potentially biased responses or evaluations of the model's outputs for evidence of unfair treatment.
Robustness
Tests in this category evaluate the model's ability to handle diverse inputs, including those with misspellings, grammatical errors, or unusual formatting. Robustness tests also assess the model's performance under adversarial conditions, such as inputs designed to confuse or manipulate the model.
Security
Security tests focus on identifying potential vulnerabilities or weaknesses in the language model that could be exploited for malicious purposes. This may include testing for vulnerabilities to prompt injection attacks, retrieval of sensitive information, or exposure to malicious code execution.
Text Clarity
This category assesses the readability, coherence, and overall quality of the model's generated text outputs. Tests may involve evaluation of factors such as grammar, spelling, sentence structure, and logical flow.
Toxicity
Toxicity tests evaluate the model's propensity to generate harmful, offensive, or inappropriate content. This may include testing for the presence of hate speech, explicit or violent content, or other forms of toxic language.
Privacy
Privacy tests assess the model's handling of sensitive or personal information, including the potential for unintended disclosure or leakage of private data. Tests in this category may involve prompts designed to elicit potentially private information or evaluations of the model's outputs for evidence of privacy violations.
Reasoning
This category focuses on evaluating the model's ability to perform logical reasoning, problem-solving, and analytical tasks. Tests may involve prompts that require the model to apply logical principles, draw inferences, or solve complex problems.
Truthfulness/Hallucination
Tests in this category assess the model's tendency to generate factually inaccurate or fabricated information, a phenomenon known as "hallucination." Tests may involve verifying the accuracy and truthfulness of the model's outputs against authoritative sources or evaluating the model's ability to distinguish factual information from fiction.
RAG
This category is focused on AI applications using a RAG system. Tests evaluate different aspects of these systems. For example, faithfulness is a metric that checks if the statements in a response match with the retrieved context. The relevancy of the answer and the retrieved context are evaluated as well.