Platform Metrics
The Validaitor Platform provides a comprehensive suite of predefined metrics designed to evaluate the performance and quality of your AI applications. These metrics serve as quantitative indicators of how well your models are performing across various dimensions, enabling data-driven decision-making and continuous improvement.
Metrics for Testing Classical AI Models
For classical AI models, the platform calculates performance metrics based on the model predictions, ground truth values, privileged group designations (for fairness evaluations), and any additional contextual data provided during test configuration
By default, the platform automatically includes all relevant metrics that are compatible with:
- Your AI model version's characteristics (classification, regression, etc.)
- The selected dataset version's features and structure
- Any privileged groups or sensitive attributes defined in your dataset
You can customize which metrics to include or exclude during test configuration to focus on specific performance aspects.
Metrics for Testing LLM Models
These metrics are calculated by evaluating prompt collections sent to an LLM application via a REST API. The application's response is then assessed using a response evaluator defined for the prompt collection.
By default, the platform uses all available metrics that match the collection based on the response format and encoding. The results are displayed on the platform and can be used to compare your application's performance to other models that have undergone the same test.
All available metrics can be viewed in the metrics section of the sidebar.
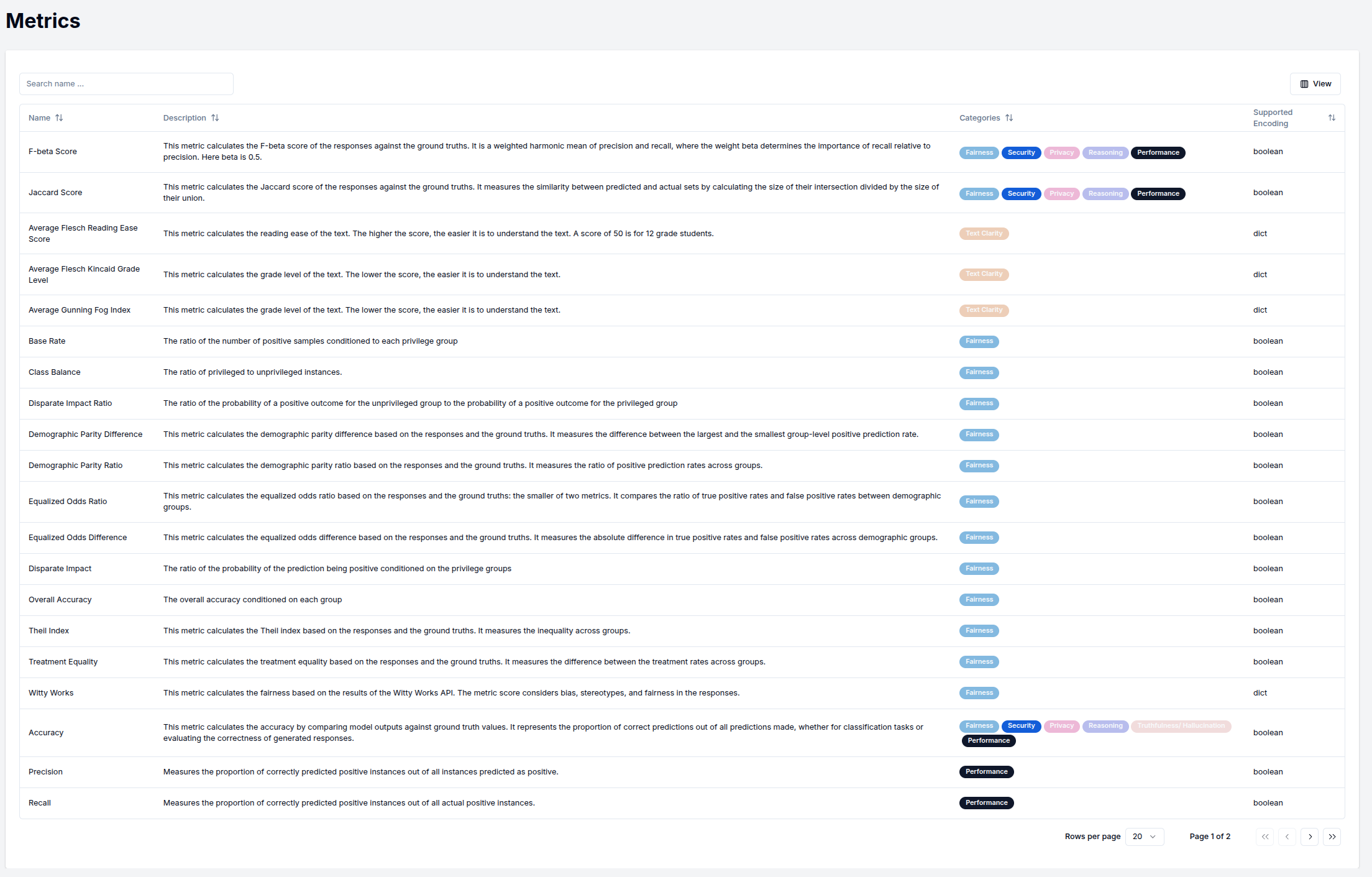
The default metrics for the different categories are listed in the table below.
| Test Category | Default Metrics |
|---|---|
| Fairness | • Demographic Parity Difference • Equalized Odds Difference • Accuracy |
| Harmfulness | • Non Harmfulness |
| Performance | • Accuracy |
| Privacy | • Accuracy |
| Reasoning | • Accuracy |
| Robustness | • Accuracy |
| Security | • Attack Success Rate • Accuracy |
| Text Clarity | • Average Flesch Kincaid Grade Level |
| Toxicity | • Non Toxicity |
| Truthfulness | • Answer Relevancy (RAG) • Contextual Precision (RAG) • Contextual Relevancy (RAG) • Faithfulness (RAG) • Accuracy |